NeSy2025 Conference Trip Report

NeSy 2025 Trip Report
Last week, I presented our work on scalable rule learning from tabular data at the Neurosymbolic Learning and Reasoning (NeSy) conference. NeSy is an annual conference that provides a forum for presenting and discussing novel scientific work on the integration of what is symbolic and sub-symbolic (neural) which hypothesized to lead to more robust, explainable and generalizable AI models.
I think our work fits to NeSy conference scope better than any other conference. Because the NeSy community see..s a value in symbolic reasoning and symbolic representations when integrated with neural networks. Pure machine learning (ML) or AI conferences overlook the value of symbolic representations.
Keynotes
Symbolic Reasoning in the Age of Large Language Models - Guy van den Broeck
Guy argued that reasoning with transformers is largely inductive, often correct across a wide range of problems, and scalable in scope, but ultimately intractable when it comes to reasoning about all possible future tokens, whereas symbolic AI relies on logic and probabilistics for deductive reasoning, making it more principled but limited in scope and often computationally intractable. The core task of reasoning about future tokens—central to applications like text generation—can be approached probabilistically by assigning likelihoods to future continuations and aligning them with constraints, or via offline reinforcement learning, where models learn joint distributions over states, actions, and rewards, then attempt to sample constrained futures at inference time, though this quickly becomes intractable for large language models. To address this, they proposed distilling a tractable circuit model—a kind of symbolic “digital twin” of the LLM—capable of reasoning explicitly with logical constraints, represented as deterministic finite automata (DFAs). This neurosymbolic approach powers systems like CTRL-G (NeurIPS 2024), which outperforms LLMs on interactive text editing and grade-school math benchmarks by ensuring constraints are strictly followed while still producing fluent text.

The advantages of CTRL-G are clear: constraints are guaranteed to be satisfied regardless of the LLM’s token distribution, it generalizes well to unseen reasoning tasks, and it provides a Bayesian, goal-directed approach to structured text generation, essentially showing how a tractable generative model can control an intractable one. More broadly, this line of work asks where reasoning algorithms went astray and suggests that today’s models should strike a balance between tractability and expressivity, as seen in probabilistic circuits. Tools like PyJuice provide an open-source foundation for scaling such circuits with techniques like monarch matrices, while newer models such as TRACE (ICML 2025) demonstrate that probabilistic circuits can align language models better than reinforcement learning, producing fluent, diverse, and safe generations with minimal training. The same principles extend beyond text: Tiramisu (ICLR 2024) applies tractable steering to diffusion models for constrained image inpainting, and even tokenization itself can be framed as a neurosymbolic problem, where enforcing symbolic constraints can help prevent adversarial manipulations and jailbreaking. Together, Guy argued that these results suggest that the future of reasoning lies in tractable, circuit-based approaches that harness the strengths of both neural and symbolic paradigms to make generative models more controllable, aligned, and robust.
Do World Models need Objects - Thomas Kipf
Thomas talked about the question of whether world models—systems designed to simulate and control what happens next—require objects as fundamental building blocks, since objects can be seen as the “symbols” of the physical world that underpin human perception, cognition, and interaction. This naturally raises the issue of whether neural architectures for world models should be explicitly informed by the compositionality of the real world, incorporating object-centric representations and hierarchies, or whether sheer scaling of current methods will suffice. The talk approaches this tension from multiple angles, including object representation learning, object-centric architectures, and the use of objects for controlling generative models, with the broader aim of understanding how representation structure and model architecture might converge when the world itself is assumed to consist of objects.
The main takeaway was that world models would benefit from object representations when the agent needs to control and/or perform actions. In other cases, Thomas timidly argued that scaling would probably be the way to go, which the NeSy audience did not like it very much.
Graph-powered Hybrid AI - Deborah McGuinness
Deborah’s (author of the wine ontology 🙂) talk was more on the historical perspective of how AI evolved over time, starting from expert systems, and recommendations for especially young researchers on how to navigate in the current AI landscape and not be intimidated by the speed and the scale of the advancements in ML. She highlighted the importance of continually surveying the landscape, keeping an eye on competition, identifying gaps worth tackling, and making creative use of emerging methodologies, all while considering shifting funding landscapes, evolving technical policies, and questions of fairness, ethics, and broader human-centered impact. A guiding framework she pointed to is the Heilmeier Catechism, which challenges researchers to state their objectives without jargon, assess current practice and its limits, clarify what is new and why it might succeed, and explain who benefits and why it matters. It also insists on confronting risks, costs, timelines, and concrete ways of testing progress, thus providing a structured way to think about not only the adoption and potential legacy of research but also its immediate and long-term significance.
Selected publications
The following are a set of publications that I found quite interesting and reflects some of the prominent research directions that the NeSy community are tackling.
Neurosymbolic Reasoning Shortcuts under the Independence Assumption - van Krieken et al.

This work addresses the problem of reasoning shortcuts (RSs) in neural networks, focusing on how the common independence assumption among symbolic concepts—while convenient for scaling probabilistic reasoning—can undermine reliability. Neural networks in this setting output a probability distribution over concept vectors, but different interpretations of input can still yield perfect downstream accuracy, as illustrated by an XOR example on MNIST where the model flips 0s and 1s yet achieves 100% accuracy, ths a reasoning shortcut. In real-world domains like autonomous driving, this translates into dangerous behavior, such as a model treating pedestrians and red lights as interchangeable as both cases lead to the output (stop the car), leading to high task accuracy but meaningless or misleading concept accuracy, often with unwarranted confidence. The challenge is to either mitigate RSs by reducing their number or, at minimum, to be aware of them. Recent approaches like the BEARS method (UAI 2024) ensemble multiple shortcuts and average them out, aiming to capture irreducible uncertainty, while the broader goal is to formalize RS awareness. The main theoretical result presented shows that under the independence assumption, neurosymbolic models can rarely be RS aware for any given probability distribution: they are structurally incapable of representing uncertainty over certain combinations of symbolic concepts. This insight settles an ongoing debate in the field by demonstrating that reasoning shortcuts are not just edge cases, but a fundamental limitation of the independence assumption, which can yield models that appear highly accurate yet reason for the wrong reasons.
A Scalable Approach to Probabilistic Neuro-Symbolic Robustness Verification - Manginas et al.
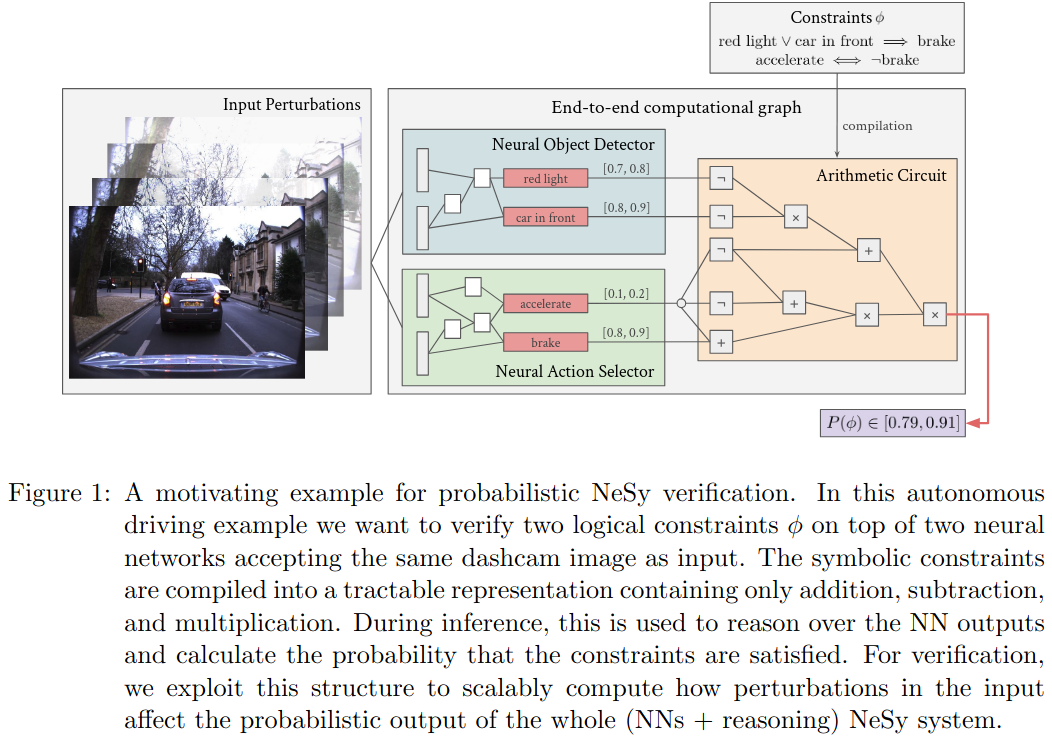
The talk began with the observation that neural systems are brittle, as shown by adversarial interventions that can easily break their predictions, and set as its goal the verification of robustness in probabilistic neurosymbolic (nesy) systems. Robustness here means that a model’s correct predictions should remain unchanged under small perturbations to the input, raising the question of how such perturbations influence the probabilities of nesy outputs. To address this, the work extends relaxation-based verification techniques—originally developed for neural models—into the nesy setting, making use of computation graphs (arithmetic circuits) to derive robustness guarantees against perturbations. The approach was tested empirically on the MNIST addition problem, illustrating how formal verification can strengthen the reliability of neurosymbolic models.
Understanding Boolean Function Learnability on Deep Neural Networks: PAC Learning Meets Neurosymbolic Models - Nicolau et al.
This work investigates the ability of deep learning systems to learn logical, symbolic concepts, building on the theoretical result that many classes of boolean formulas are learnable in polynomial time and asking what this looks like in practice with neural networks. The methodology involves generating datasets tailored to specific formulas, with balanced positive and negative examples, and training a separate MLP per formula. Experiments span model-sampling benchmarks and combinatorial optimization problems like graph coloring, probing the relationship between satisfiability and learnability—for example, whether harder-to-satisfy formulas are also harder to learn. Interestingly, results show that medium-sized formulas can be easier to learn than small ones, that learning success can depend on structural properties of the problem, and that tasks defined over random graphs appear easier for MLPs. A counterintuitive finding is that formulas with fewer variables often require more neurons to learn, and that underconstrained problems are harder to solve than overconstrained ones. Overall, MLPs consistently achieve very high accuracy—99%+—across all studied formulas, demonstrating that relatively small and shallow networks can serve as powerful approximators of symbolic concepts, generalizing better than purely rule-based or symbolic approaches and offering insight into how neurosymbolic methods might be better constructed and applied.
Beyond the convexity assumption: Realistic tabular data generation under quantifier-free real linear constraints Stoian et al.
This work was originally published at ICLR 2025 and the authors had an extended abstract at the conference.
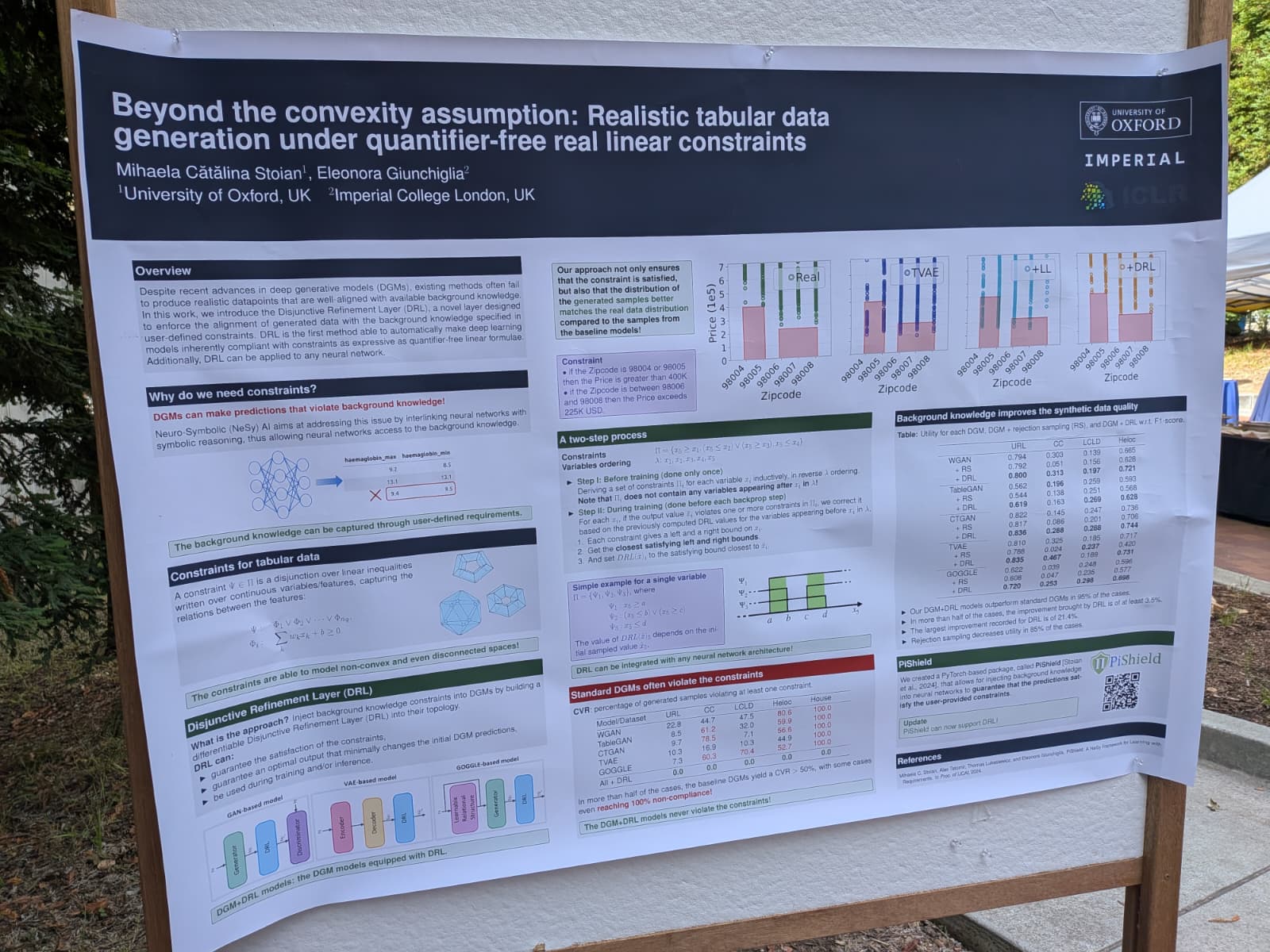
The main idea was that when generating tables to be used for e.g., training larger models for domains with data scarcity, how do we make sure that the generated table is realistic and reflects the domain using constraints. The authors introduce the Disjunctive Refinement Layer (DRL), a novel component designed to ensure that synthetic tabular data generated by deep generative models (DGMs) adheres to user-defined constraints. These constraints are expressed using Quantifier-Free Linear Real Arithmetic (QFLRA) formulas, which can define complex relationships among features, including non-convex and disconnected regions. DRL operates by adjusting the output of the DGM to satisfy these constraints while maintaining the integrity of the generated data. It does so by applying a refinement process that minimally alters the generated data to make it compliant with the specified constraints. This process ensures that the generated data points are not only realistic but also aligned with the background knowledge encoded in the constraints.
This reminded me of how synthetic tabular data is generated e.g., using structural causal models as in TabPFN. The main ‘limitation’ of the work is that the constraints are user-specified rather than auto-generted. Constraints could also be sampled/learned from large-scale knowledge graphs, and then be used to guide tabular data generation together with structural causal models to obtain more realistic datasets to develop foundation models.